Migrating to Isolated Durable Functions
When you create Azure Functions in C#, you currently have a choice between "in-process" and "isolated process" models. The "in-process" model is the one that you're likely familiar with if you've been using .NET Azure Functions for a while. However, the "isolated process" model is going to become the only supported model for new versions of .NET going forwards, as can be seen in this roadmap diagram:
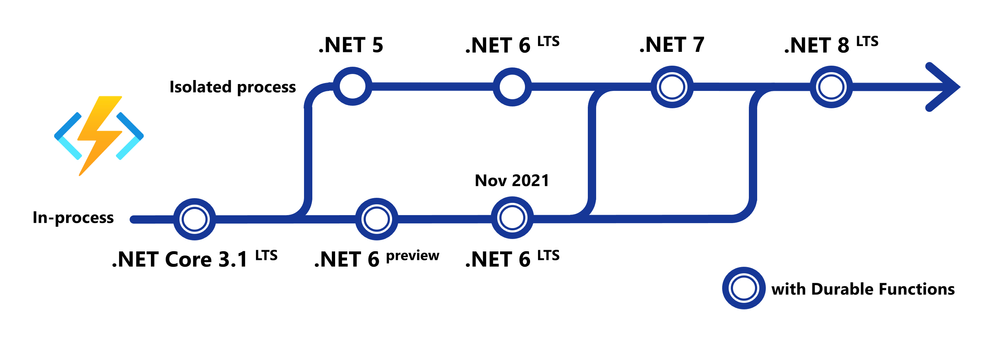
Until recently, one of the big gaps in the "isolated process" model was support for Durable Functions. It simply wasn't possible until the release of .NET 7 to use Durable Functions in an isolated model function app.
And at the time of writing (in Jan 2023), Durable Function support for isolated process is still not officially released although there is a release candidate available.
Is it time to switch?
Given that the "isolated process" model is clearly the future for Azure Functions, my recommendation would be to create any new Function Apps using .NET 7 and the isolated model.
This does mean you might need to learn a few new things and miss a couple of capabilities that you were used to if you were familiar with the old model. However, the process of converting in-process to isolated process is quite painful, so it's probably best for new projects to start as isolated to avoid the need for migration in the future.
For existing projects, I'd recommend not rushing to port them over, as the isolated model is still fairly new and is missing some convenience features from the old model.
Converting in-process Durable Functions to the isolated model
I decided to try converting an existing Durable Functions application to get a better understanding of the changes. I chose my "e-Commerce sample", that I've used for various presentations. This includes a variety of bindings including SendGrid for sending emails, blob storage for creating files, and table storage as a simple database.
My approach was to create a brand new empty isolated process Azure Functions project and copy my existing functions into that project.
There are a few key differences to notice. First is that you'll need to reference completely different NuGet packages. Here's the packages I was referencing for my in-process project, which includes some extensions for things like blob storage and tables as well as the Durable Functions extension:
<PackageReference Include="Microsoft.Azure.WebJobs.Extensions.DurableTask" Version="2.9.0" />
<PackageReference Include="Microsoft.Azure.WebJobs.Extensions.SendGrid" Version="3.0.2" />
<PackageReference Include="Microsoft.Azure.WebJobs.Extensions.Storage" Version="5.0.1" />
<PackageReference Include="Microsoft.Azure.WebJobs.Extensions.Tables" Version="1.0.0" />
<PackageReference Include="Microsoft.NET.Sdk.Functions" Version="4.1.3" />
However, for an isolated model function app, we change all of those for NuGet packages beginning with Microsoft.Azure.Functions.Worker.... Here's the NuGet packages I referenced, which includes the isolated versions of the extensions as well as the release candidate support for Durable Functions:
<PackageReference Include="Microsoft.Azure.Functions.Worker.Extensions.Http" Version="3.0.13" />
<PackageReference Include="Microsoft.Azure.Functions.Worker.Extensions.SendGrid" Version="3.0.2" />
<PackageReference Include="Microsoft.Azure.Functions.Worker.Extensions.Storage" Version="5.0.1" />
<PackageReference Include="Microsoft.Azure.Functions.Worker.Extensions.Tables" Version="1.0.0" />
<PackageReference Include="Microsoft.Azure.Functions.Worker.Sdk" Version="1.7.0" />
<PackageReference Include="Microsoft.Azure.Functions.Worker" Version="1.10.0" />
<PackageReference Include="Microsoft.Azure.Functions.Worker.Extensions.DurableTask" Version="1.0.0-rc.1" />
Other differences are that FUNCTIONS_WORKER_RUNTIME will now be set to dotnet-isolated, and you will be building an executable.
Function changes
If you cut and paste your functions from an existing Durable Functions project into an isolated functions project, it quickly becomes apparent that there are a lot of breaking changes. It took me a long time just to get everything compiling again.
For example:
- instead of the
FunctionNameattribute we now haveFunctionattribute. - Instead of a
HttpTriggerbinding to aHttpRequestparameter and the method returning anIActionResult, we now bind to aHttpRequestDataand returnHttpResponseData. This includes learning how to use theCreateResponsemethod ofHttpRequestData. - Instead of taking an
ILoggerparameter, we take aFunctionContextand callGetLoggeron it
And the Durable Functions bindings have also changed a lot:
- Instead of binding the
[DurableContext]attribute toIDurableOrchestrationClient, we now bind it toDurableClientContext- this has a
Clientproperty which is an instance ofDurableTaskClient - most of the methods have new names. A few examples:
StartNewAsyncinstead ofScheduleNewOrchestrationInstanceAsyncCreateCheckStatusResponseinstead ofCreateHttpManagementPayloadGetInstanceMetadataAsyncorGetInstancesinstead ofGetStatusAsyncPurgeInstanceMetadataAsyncinstead ofPurgeInstanceHistoryAsync
- this has a
- Instead of binding the
[OrchestrationTrigger]attribute toIDurableOrchestrationContext, we now bind it toTaskOrchestrationContext- this hasn't changed as dramatically, but there are differences
- e.g. instead of
CallActivityWithRetryAsync, you useCallActivityAsyncand pass inTaskOptions.FromRetryPolicy
- My activity functions required the fewest changes, although I switched from using bindings to getting at Azure SDK types via dependency injection for reasons I'll discuss shortly.
My goal in this post is not to provide an exhaustive guide to porting, but to show that numerous changes are required, and so you may prefer to keep existing projects on the in-process model for the time being.
Are bindings worth it?
One of the selling points of Azure Functions is that the bindings can simplify the work required to connect to external services, such as blob storage, queues and table storage. To a certain extent this remains true with the isolated model, but there are some down-sides to be aware of.
One of the key disadvantages is that the bindings don't necessarily expose all of the capabilities of the underlying service, and their capabilities also become even more restricted in the isolated process model, as the variety of types you can bind to is greatly reduced.
For example, with in-process functions you could bind to a BlobContainerClient allowing you to access the full functionality of the Azure SDK for whatever blob operations you require. The isolated process binding options are much more limited, although I believe work is planned to support bindings to Azure SDK types which would be excellent.
I also ran into real problems getting my Table Storage bindings working at all in the new model. I'm not sure what the issue was exactly, but it caused me to explore how much effort it would be to simply use the Table Storage SDK directly.
As it turns out, it's very simple. In Program.cs I used the AddAzureClients method from the Microsoft.Extensions.Azure NuGet package to add blob service and table service client.
services.AddAzureClients(clientBuilder =>
{
clientBuilder.AddBlobServiceClient(Environment.GetEnvironmentVariable("AzureWebJobsStorage"));
clientBuilder.AddTableServiceClient(Environment.GetEnvironmentVariable("AzureWebJobsStorage"));
});
With this set up, it's easy to inject BlobServiceClient or TableServiceClient into your functions (either by making the constructor parameters, or by using FunctionContext). This means we can access the full power of the Azure SDKs in our functions. For example, here we fetch a TableStorageClient from the DI container and use it to get a TableClient for the Orders table:
var tableServiceClient = functionContext.InstanceServices.GetRequiredService<TableServiceClient>();
var tableClient = tableServiceClient.GetTableClient("Orders");
As you can see, the amount of code we need to write to directly use the Azure SDKs is fairly minimal, so bindings are not necessarily providing a huge simplification to your application. Having said that, once isolated model supports binding to SDK types, there is potential for a small amount of code simplification by using them.
Unfortunately with triggers you are a bit more limited in your options, and my understanding is that at the moment, there are still some missing features. For example, when receiving an Azure Service Bus message, I am not aware that there is currently any way to access the message metadata collection which is a serious limitation. Update: actually I have found out how to get at message metadata
Serialization issues
One of the biggest pain points I ran into during this process was subtle changes to how JSON serialization works. There's quite a lot of serialization going on in a typical Durable Functions app, as the inputs and outputs to orchestrators and activity functions get serialized to JSON. You might also use it for custom statuses.
And of course any HTTP triggered functions you write to interact with your orchestrations are going to be serializing and deserializing the HTTP body payloads.
This resulted in a mixture of usages of Newtonsoft.Json and the newer System.Text.Json, which in turn meant that sometimes I was getting camelCased JSON and in other places I was getting PascalCased.
I tried some options to globally set the naming policy but ended up breaking other things. In the end I settled for defining my own serializer:
static readonly ObjectSerializer serializer = new JsonObjectSerializer(new JsonSerializerOptions
{
PropertyNamingPolicy = JsonNamingPolicy.CamelCase,
DefaultIgnoreCondition = JsonIgnoreCondition.WhenWritingNull
});
And then using it explicitly in the responses from my HTTP functions:
await resp.WriteAsJsonAsync(new { order.Id }, serializer);
Summary
The isolated model is here and is the future of Azure Functions and Durable Functions. However, migrating to it is a non-trivial process at the moment. I suggest avoiding the migration for now if you can (at least until the integration with Azure SDK types is improved), and consider using the isolated model for all new development.
I also noticed while I was browsing the sample apps that it looks like there is another(!) new programming model coming to Durable Functions, which is a "typed" model and relies on code generation. You can see an example of it here - although I've struggled to find any documentation about it so I'm not sure how "official" this is.
You can keep up to date with the .NET on Azure Functions roadmap here.