Faster Querying with Serverless Materialized Views
In this article I want to discuss the materialized view pattern and why I think serverless is a good match for it. I've written this as my submission to the "Serverless September" initiative. Be sure to check out the other great contributions to this series.
Materialized Views
Let's start with a brief overview of what is meant by a "materialized view". In an ideal world, we'd store all of our data in a database that was perfectly optimized for every query we threw at it. No matter what question we asked of the data, it would respond quickly and efficiently.
In the real world, unfortunately, that's just not possible. Whether you're storing your data in a relational database like SQL Server or a document database like Cosmos DB, there are going to be occasions where the queries you want to run are simply too slow and costly.
The materialized view pattern is a simple idea. We build a new "view" of the data that stores the data in just the right way to support a particular query. There are several different approaches to how the materialized view is generated, but the basic idea is that every time we update application data, we also update any materialized views that depend on that data.
You can create as many materialized views as you want. It's quite common to create one for a specific view on a web-page or mobile application, since performance is especially important when an end user is waiting for a page-load.
An Example Scenario
Let's consider a very simple example scenario. Imagine we have an e-Commerce website. Our database will store products (all the things we sell) and orders (all the things we've sold).
If our database is a relational database, then we'd probably have at least three tables - one for the products, one for orders, and one for "order lines" as a single order may be for multiple products.
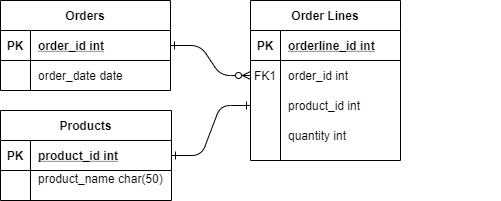
And if our database was a document database, then we'd probably use a document for each product and a document for each order, including its "order lines". Here's a simplified representation of what an order document might look like in a document database:
{
'id': 1234,
'customerEmail': '[email protected]',
'lines': [
{ 'productId': 129512, 'quantity': 1},
{ 'productId': 145982, 'quantity': 2}
]
}
So far, so good. But let's imagine that when a customer views a product, we also want to show them some recommendations of a few products that other customers who bought this item also purchased.
Whether we used a relational database or a document database, this query is perfectly possible to implement. All we need to do is to find all orders that include the product currently being viewed, and then group all the "order lines" by product id, sort them by the most popular, and take the top few rows. Simple! But very slow and expensive. If we have millions of orders in our database the query will probably take far too long to complete for the web-page to load without timing out.
Instead we can create a materialized view that is specifically designed to return the product recommendations. For each product we could keep a running total of the counts of other items purchased at the same time. And now what was previously an expensive aggregate operation across all order lines in the entire database becomes a simple lookup by product id.
Eventual Consistency
Having decided we want a materialized view, we have a problem. How will we keep the view up to date?
Basically every time a new order comes in, as well as saving it to the database, we also need to update the materialized view. If a new order is placed for products A and B, then we need to update two rows in our materialized view: the row for product A to add B as a recommendation, and vice versa.
The most common approach taken for materialized view generation is asynchronous updates. For example, when a new order comes in, we might publish an message to an event bus, and a subscriber to that message can be responsible for updating the materialized view.
This approach has several benefits. It means the code storing a new order can remain quick, and the potentially slower operation of updating the materialized view can happen in the background later. It also means we can scale out with many materialized views being updated in parallel.
But it does also mean that there will be a short window of time where our materialized view isn't fully up to date. This is known as the problem of "eventual consistency". The recommendations materialized view might not be fully up to date immediately, but will eventually become so.
This idea can worry people. Isn't it bad to show our customers data that isn't fully up to date? Actually it turns out that in many cases it doesn't matter as much as you might think. In our example, it hardly matters at all. So what if the recommendations I see for related products aren't perfectly up to date?
Of course, the asynchronous approach to updating materialized views isn't strictly required. There are ways to put the update to the main data and all materialized views inside a single transaction, so they are always consistent. However, this comes at a significant performance cost penalty and may also involve the complexities of distributed transactions.
Why Serverless?
Now we've considered what a materialized view pattern is, and why we might want to do it, let's see why I think serverless is a good fit for implementing these views.
First, materialized view updates are usually event-driven. And serverless "Functions as a Service" frameworks like Azure Functions are great for implementing event handlers. You could create an Azure Function for each materialized view you want to keep up to date. The built-in scalability of Azure Functions means that even if you have lots of materialized views to update, they can be processed in parallel.
Second, sometimes you need to rebuild an entire materialized view from scratch. This is common when you're introducing a new materialized view, so you can't just subscribe to updates to the source data - you need to go back to the beginning. This generates a significant backlog of work, and serverless platforms like Azure Functions have the capacity to rapidly scale out to help you catch up quickly.
Alternatively, sometimes materialized views are generated using a schedule. For example, maybe every night at midnight you completely rebuild one of the views. Again, this is something that serverless is great at - it's easy to create a timer-triggered Azure Function (although if you're processing a lot of data in a single function you'll need to take care not to time out - in the consumption plan Azure Functions have a time limit which defaults to 5 minutes)
Finally, it can be very hard to predict ahead of time how much compute resource is needed to maintain a materialized view. Some views may require very infrequent updates, while others are constantly churning. Some changes can come in bursts. Again, having a platform that dynamically scales out to meet demand, but also can scale to zero to save money during idle periods gives you a cost-effective way to pay only for the compute you need.
Cosmos DB change feed
The materialized view pattern can be implemented against any database, including SQL Database and Cosmos DB. In fact, it's quite common to pair this pattern with "event sourcing", where you simply store "events" that represent the changes to application state, rather than the current state of the application, which is typically what a regular database would store.
Cosmos DB has a really helpful feature called the "change feed" which allows you to replay all the changes to documents in a collection. That is to say, every time a new document is created or updated, a new entry appears in the change feed. You can then either subscribe to that change feed, to be notified about every change, or replay it from the start, to receive notifications of all historic changes. This makes it ideal for both generating a new materialized view and keeping it up to date.
The change feed needs to keep track of how far through the backlog of change events you are, and this is done by maintaining a "lease" which is very simply stored in a container in your CosmosDB database.
Azure Functions comes with a built-in trigger called the CosmosDBTrigger that makes it really easy to subscribe to these change notifications, and use them to update your materialized views. And it gives you the changes in batches (typically 100 changes in a batch), enabling you to make your materialized view update code more efficient.
Sample application
To demonstrate serverless materialized view generation with the Cosmos DB change feed, I decided to create a very simple proof of concept application. The scenario I chose to implement was the e-Commerce example I described above, where we want to generate product "recommendations" based on order history from all customers.
I chose Cosmos DB for my database, and my database design is very simply a products collection which holds a document per product. And an orders collection which holds a document for each order. For the recommendations, I could have created a recommendation document per product (so the recommendation materialized view was entirely separate), but for this demo I decided to store the recommendations directly in the product document itself.
I made a very simple console application to auto-generate products and random orders that use the products. Here's the code for the product generator and the order generator.
I also wrote a function to produce the recommendations on the fly without the aid of a materialized view. This shows off quite how slow and expensive performing this query is. (With CosmosDB, every query consumes a number of "request units" (RUs) and the more orders you have, the more RUs this query will consume) It was already getting very slow with just a few thousand orders in the database, and I suspect that by the time there are millions of orders, it simply wouldn't be possible to run this in real-time.
Then I created an Azure Function application that contained a single function to update my materialized view. This uses a CosmosDBTrigger which means this function will be triggered every time there is an update to documents in the collection we're monitoring. In our case, it's the orders collection, so any new orders will trigger this function. I also need to specify where the "lease" is stored that will keep track of how far through the updates we are. And I've set StartFromBeginning to true, although technically for a materialized view like our recommendations there is no need to do that if we don't mind starting with no recommendations.
I'm aso using a CosmosDB binding so that I can perform additional queries and updates to the products collection. Here's the function declaration:
[FunctionName("UpdateRecommendationView")]
public static async Task Run([CosmosDBTrigger(
databaseName: databaseName,
collectionName: Constants.OrdersContainerId,
ConnectionStringSetting = connectionStringSettingName,
LeaseCollectionName = "leases",
StartFromBeginning = true,
CreateLeaseCollectionIfNotExists = true)]
IReadOnlyList<Document> input,
[CosmosDB(
databaseName: databaseName,
collectionName: Constants.ProductsContainerId,
ConnectionStringSetting = "OrdersDatabase")] DocumentClient productsClient,
ILogger log)
Inside the function, the input parameter that the CosmosDBTrigger is bound to contains a list of updates. Each update includes the full document contents, so we can simply loop round and examine each order. In our case, for each order that is for more than one product we must update the product document for each product in that order to increment its count of purchases.
Obviously this could be quite slow, but that's one of the advantages of building these views asynchronously - it's happening in the background and not affecting the end user's experience. I could also rework this code slightly to take advantage of the batched nature of the updates, which would possibly reduce the number of document updates we need to make for each batch - currently we would update the same product more than once if it featured in multiple orders in the batch.
I did make one small performance enhancement, which is to ensure that the recommendation list size for each product doesn't grow above 50, just using a very simplistic technique. Obviously a real-world recommendations engine would be more sophisticated.
foreach (var doc in input)
{
Order order = (dynamic) doc;
log.LogInformation("Order: " + order.Id);
if (order.OrderLines.Count <= 1)
{
// no related products to process
continue;
}
foreach (var orderLine in order.OrderLines)
{
var docUri = UriFactory.CreateDocumentUri(databaseName, Constants.ProductsContainerId, orderLine.ProductId);
var document = await productsClient.ReadDocumentAsync(docUri,
new RequestOptions { PartitionKey = new PartitionKey("clothing") }); // partition key is "/Category" and all sample data is in the "clothing" category
Product p = (dynamic) document.Resource;
if (p.Recommendations == null)
{
p.Recommendations = new Dictionary<string, RelatedProduct>();
}
log.LogInformation("Product:" + orderLine.ProductId);
foreach (var boughtWith in order.OrderLines.Where(l => l.ProductId != orderLine.ProductId))
{
if (p.Recommendations.ContainsKey(boughtWith.ProductId))
{
p.Recommendations[boughtWith.ProductId].Count++;
p.Recommendations[boughtWith.ProductId].MostRecentPurchase = order.OrderDate;
}
else
{
p.Recommendations[boughtWith.ProductId] = new RelatedProduct()
{
Count = 1,
MostRecentPurchase = order.OrderDate
};
}
}
if (p.Recommendations.Count > 50)
{
// simplistic way to keep recommendations list from getting too large
log.LogInformation("Truncating recommendations");
p.Recommendations = p.Recommendations
.OrderBy(kvp => kvp.Value.Count)
.ThenByDescending(kvp => kvp.Value.MostRecentPurchase)
.Take(50)
.ToDictionary(kvp => kvp.Key, kvp => kvp.Value);
}
// update the product document with the new recommendations
// (another optimization would be to not update if the recommendations hadn't actually changed)
await productsClient.ReplaceDocumentAsync(document.Resource.SelfLink, p);
}
}
Summary
The materialized view pattern is a very useful and powerful way to enable complex queries to be performed rapidly. The supporting views can be generated asynchronously, and serverless platforms like Azure Functions are a great fit for this. The CosmosDB change feed greatly simplifies the task of setting this up, and has built-in support in Azure Functions.
Despite not having used the CosmosDB change feed processor before I found it really quick and easy to get up and running with it. You can learn more about the Cosmos DB change feed here.
Comments
Very cool. Can def. see this as a way to offset the cost of using a document store in terms of reporting, etc. In many ways, I'd prefer to re-calculate the read-only view one time (when needed) vs. potentially running the entire query over-and-over again.
James HickeyLove this approach 👍